TAM
Capex Spending by Hyperscalers
Godman Sachs:
386Bill$ in 2205,
471 Bill$ in 2026,
543 Bill$ in 2027.
Major Data Center players
| Company | Current operational capacity (GW) | Planned expansion (GW) | Notes / expected timeline (short) |
|---|---|---|---|
| Aligned Data Centers | ~5.0 GW | Part of buyer’s $30B–$100B deployment plan; additional campus growth expected 2026+. | Reuters / industry coverage state ~5 GW across ~50–80 campuses; deal expected to close H1 2026 (regulatory permitting). |
| QTS | >2.0 GW | Ongoing campus expansions; company marketing cites growth driven by AI demand (timelines vary by site). | QTS homepage and investor materials state “over two gigawatts” of capacity; site-by-site expansions rolling out. |
| NTT (Global / NTT DATA) | ~2.0+ GW | Recent land acquisitions to add ~324 MW (Phoenix campus) and push some campus totals nearer to 600 MW (regionally) — first new facilities scheduled ~FY2028 for some projects. | NTT public pages cite “2K+ MW critical IT load” across global footprint; multiple new campuses announced (some first openings ~2026–2028). |
| Vantage Data Centers | ~2.6 GW | Large “Frontier” Texas mega-campus 1.4 GW announced (multi-year build); many regional projects — total planned pipeline >1 GW depending on campus. | Vantage cites >2.6 GW of combined planned/existing capacity; Frontier campus buildouts are multi-year (2026–2030+ timelines). |
| Iron Mountain Data Centers | ~1.2+ GW total potential capacity (company figure). | Announced +350 MW in Virginia (200 MW Richmond + 150 MW Manassas) — phased builds into 2026–2028. | Iron Mountain investor release notes >1.2 GW potential and specific campus programs (Miami, India, Virginia) with phased timelines. |
| CyrusOne | Hundreds of MW | Example: FRA7 campus +61 MW local generation by 2029; Bosque County (Texas) site power deals (MWs) announced — phased to 2028–2029. | Company press releases provide site-level MW additions and power partnerships (timelines often through 2028–2029). |
| Equinix | (No single GW number published) — company energy deals would supply >1 GW of electricity to its campuses | Ongoing campus expansions and shifts to multi-100 MW campuses; nuclear/advanced nuclear PPAs preordered (multi-year rollouts). | Equinix publishes detailed annual filings (MW additions, renewable PPAs) but not a clean single “GW operational” total; energy contracts >1 GW announced in 2025. |
| Digital Realty | (No single GW total published) — company reports 1.5 GW of contracted renewable generation (clean-energy figure). | Large land and campus developments globally; site-by-site capacity expansions (timelines vary by metro; see company Impact Report). | Digital Realty disclosures focus on MW per campus and renewable commitments; total IT-load GW is not published as a single figure in the impact report. |
| Switch / The Citadel | Key campus examples: Citadel NV site ~0.65 GW (650 MW) for that campus; SuperNAP Las Vegas ~315 MW (expandable). | Ongoing campus expansions and new site permits (Europe, US) — timelines site-specific (2025–2027 typical). | Switch operates multiple large campuses — flagship Citadel figures are often cited (hundreds of MW per campus). Aggregate company total is multiple campuses (hundreds of MWs to >1 GW depending on expansion timing). |
| AWS Amazon | Indicator: AWS reports ~9 GW of renewable energy capacity contracted (regional project figures) and multiple large PPAs (not a direct IT-load GW). | AWS continuing to sign large PPAs (e.g., 1.92 GW nuclear PPA example) to support further expansion — multi-year rollouts (2025–2028+). | Hyperscalers disclose energy/power deals rather than a single consolidated IT GW figure; those energy contracts are useful proxies for scale but are not identical to “IT load capacity.” |
| Microsoft | Indicator: Microsoft has contracted tens of GW of clean energy (public disclosures cite large GW-scale commitments — e.g., quotes ~34 GW of carbon-free contracts in recent coverage). | Large new hyperscale AI datacenters announced (e.g., Wisconsin AI facility timeline: online early 2026) and multi-GW contracted energy pipeline supporting further builds. | Microsoft reports large renewable/clean energy contracting; used here as a scale indicator for global data-center footprint (not a direct single “operational GW” figure). |
| Indicator: Google signed ~8 GW of clean energy capacity in 2024 (public sustainability disclosures). | Large campus and region builds continuing (examples: new Belgium expansion, India campus announcements) — multi-year rollouts. | As with other hyperscalers, Google reports energy contracts / MWh usage which indicate very large scale; individual campus MWs and build timelines vary. |
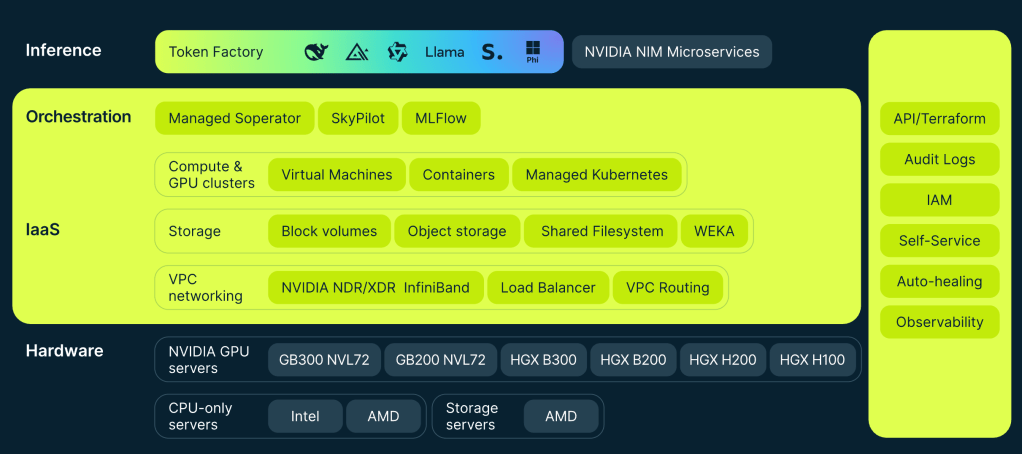
AI Infra Software Stack
| Layer | Description / Role | Key Providers / Projects |
|---|---|---|
| End-user Application / AI-as-a-Service layer | User-facing AI services (chatbots, recommendation engines, vision APIs) built atop the models | OpenAI (ChatGPT API), Anthropic, Cohere, Hugging Face Inference API, Google Vertex AI |
| MLOps / Model Lifecycle & Monitoring | Experiment tracking, versioning, deployment pipelines, metrics, drift detection, A/B testing | Weights & Biases; MLflow; Kubeflow; TFX; Neptune.ai; Seldon; Arize; Evidently |
| Inference / Serving / Model Deployment | Exposing models as APIs, batching, scaling, low-latency serving, quantization, caching | NVIDIA Triton Inference Server; TorchServe; TensorFlow Serving; Ray Serve; BentoML; ONNX Runtime |
| Model Parallelism / Trainer / Orchestration / Scaling | Distributed training orchestration, parallel splits, scheduling | PyTorch Lightning, Hugging Face Accelerate, DeepSpeed, Alpa, Ray, Colossal-AI, Megatron |
| AI Framework / Training & Inference Engine | High-level model definition, optimizers, autograd, training loop, inference serving | PyTorch, TensorFlow, JAX; Hugging Face Transformers, DeepSpeed, Megatron-LM, Fairseq |
| Collective-communication / Distributed primitives | All-reduce, broadcast, reduce-scatter, communication topology mgmt across GPUs / nodes | NVIDIA NCCL; AMD RCCL; Horovod (MPI); Gloo; DeepSpeed comm modules |
| Low-level GPU Runtime / Accelerator SDKs / Libraries | Runtime APIs, memory mgmt, kernel launches, low-level primitives (BLAS, convolution, comms) | NVIDIA CUDA / cuDNN / NCCL; AMD ROCm; Intel oneAPI / oneDNN; Habana SynapseAI; Google XLA |
| GPU Drivers & Firmware / Kernel-level runtime | Low-level drivers, hardware control, firmware, kernel modules, ISA/runtime bridging to OS | NVIDIA (GPU driver, CUDA driver), AMD (ROCm driver), Intel OneAPI, vendor firmware |
Difference between Cloud IAAS provider like AWS and AI IAAS provider like Coreweave
| Layer of the Stack | Traditional Cloud IaaS (e.g., AWS, Azure VM) | CoreWeave AI Cloud (Bare Metal) | Difference / Note |
| 7. Workload | Application (AI model, inference code, etc.) | Application (AI model, inference code, etc.) | No difference. This is what the user runs. |
| 6. Orchestration | Kubernetes or other schedulers (runs on VM) | Kubernetes (runs directly on OS/Bare Metal) | Kubernetes is used, but is closer to the metal on CoreWeave. |
| 5. Runtime | Container Runtime (Docker, containerd) | Container Runtime (Docker, containerd) | No difference. |
| 4. Operating System (OS) | Guest OS (Linux/Windows) inside the VM | Host OS (runs directly on hardware) | OS management moves from the user’s VM to the physical server OS/Host OS. |
| 3. Virtualization | Hypervisor (e.g., KVM, Xen, VMware) | NONE (ELIMINATED) | KEY DIFFERENCE: This layer is removed to maximize performance. |
| 2. Hardware Abstraction | Virtual Hardware (vCPUs, vRAM, vNICs, vGPUs) | Host OS/Drivers access physical hardware directly | Eliminates the abstraction overhead. |
| 1. Physical Hardware | Server/GPU/Networking | Server/GPU/Networking (NVIDIA, InfiniBand) | No difference. The physical foundation. |